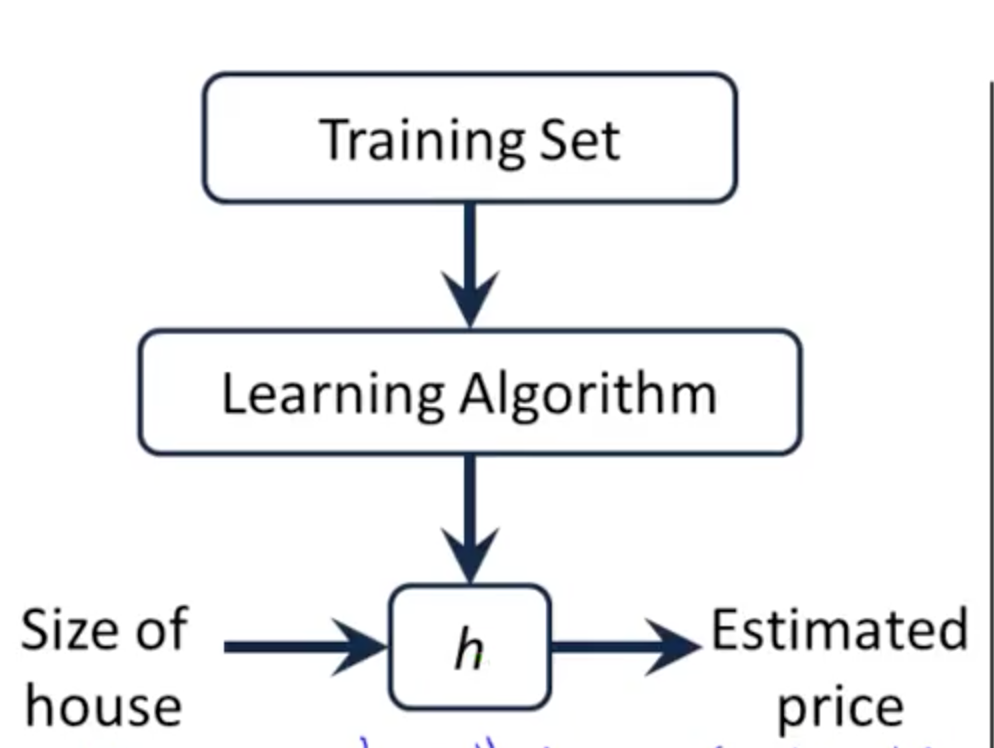
求代价函数最小值问题,如果是正规方程,我们可以对每个参数值求导并令导数为0。
我们队最小二乘法进行参数求导,最终得到的关系如上图所示

如果使用了正规方程,那么就不需要进行特征缩放(特征变量归一化处理,便于进行梯度下降)取相似范围,因为最终算出来的结果是一样的.
我们可以使用matlab或者Octave来进行正规方程的计算。
推荐使用pin函数来进行计算,因为正规方程中设计的矩阵逆运算,即是矩阵没有逆矩阵也会给出结果。
那么是什么导致举证不可逆呢?
存在多余的相似特征,我们可以删除他
太多的特征导致行数小于列数,我们可以通过删减特征以使举证为方阵,矩阵的可逆是建立在方阵基础上的
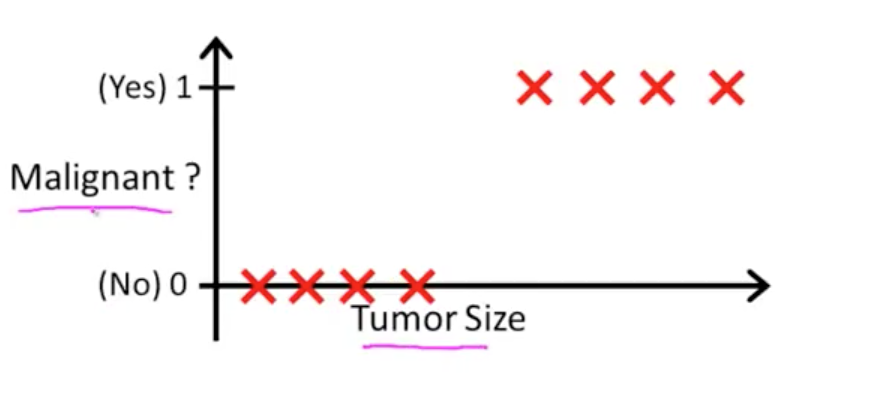




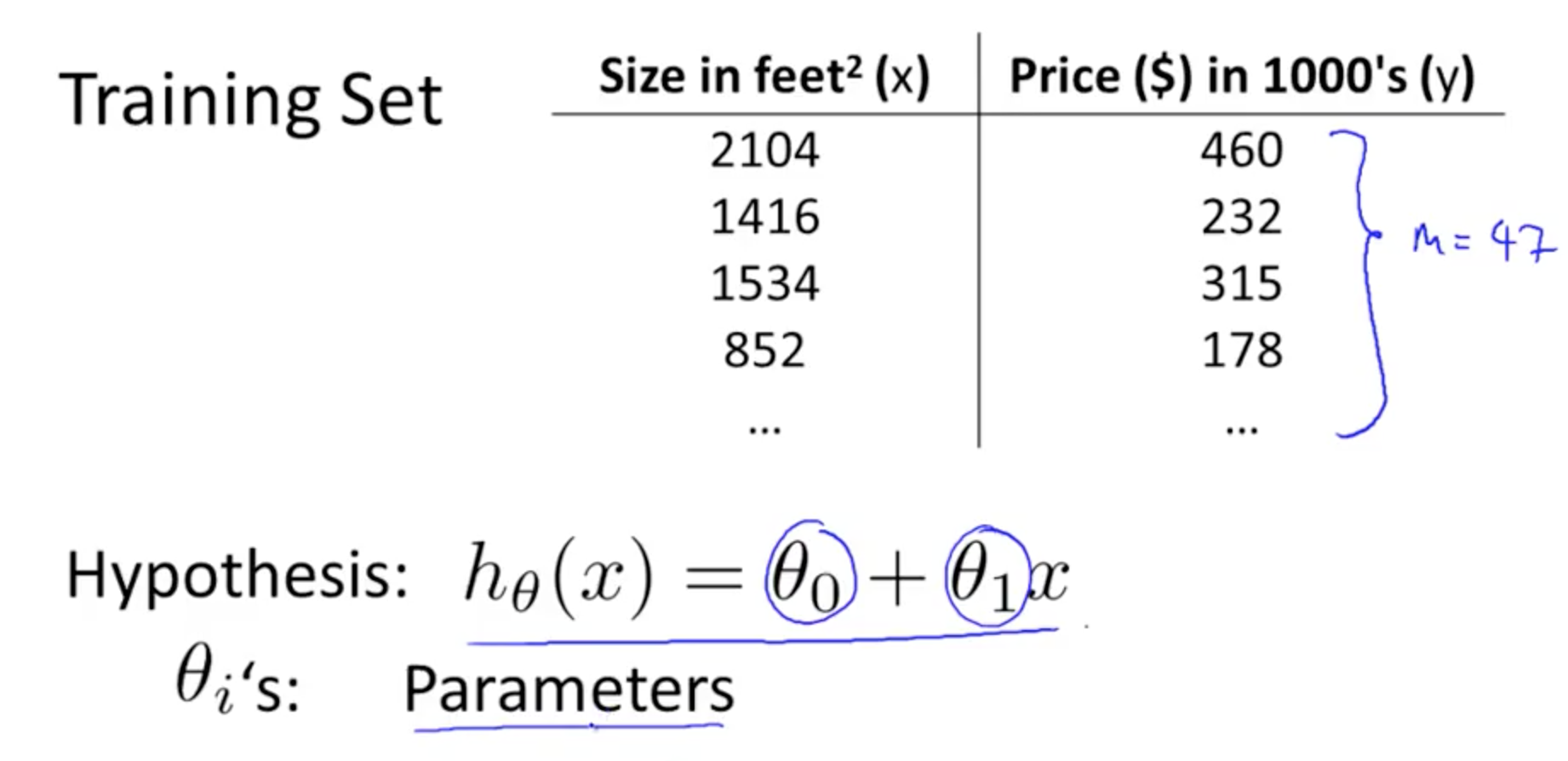
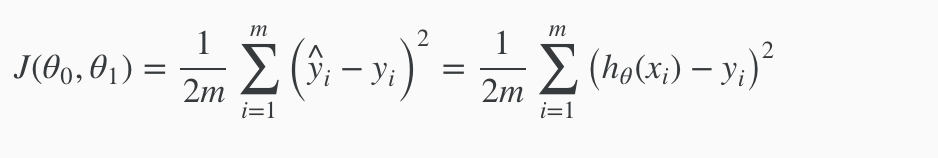

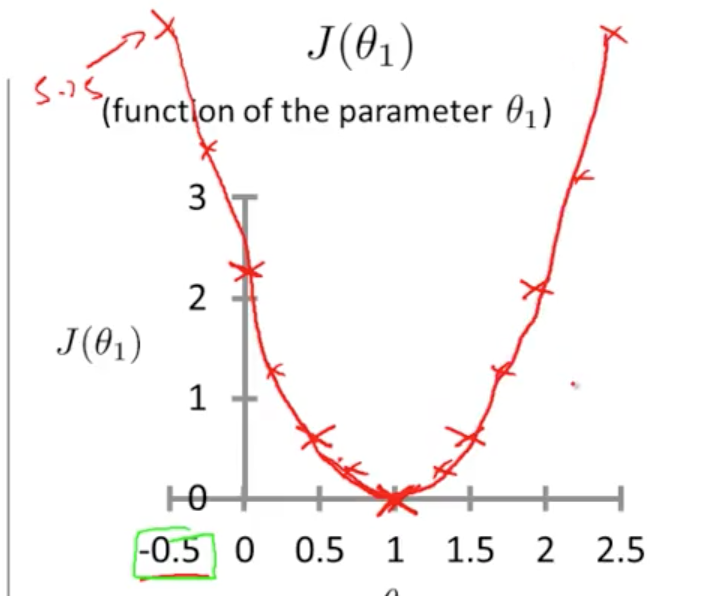
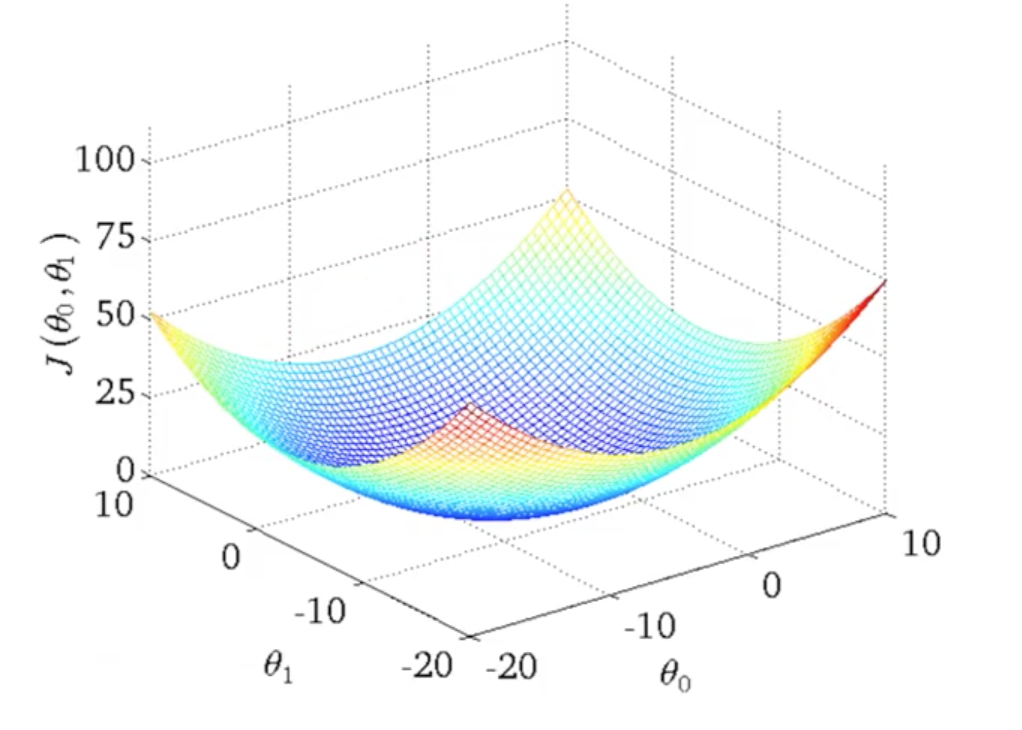
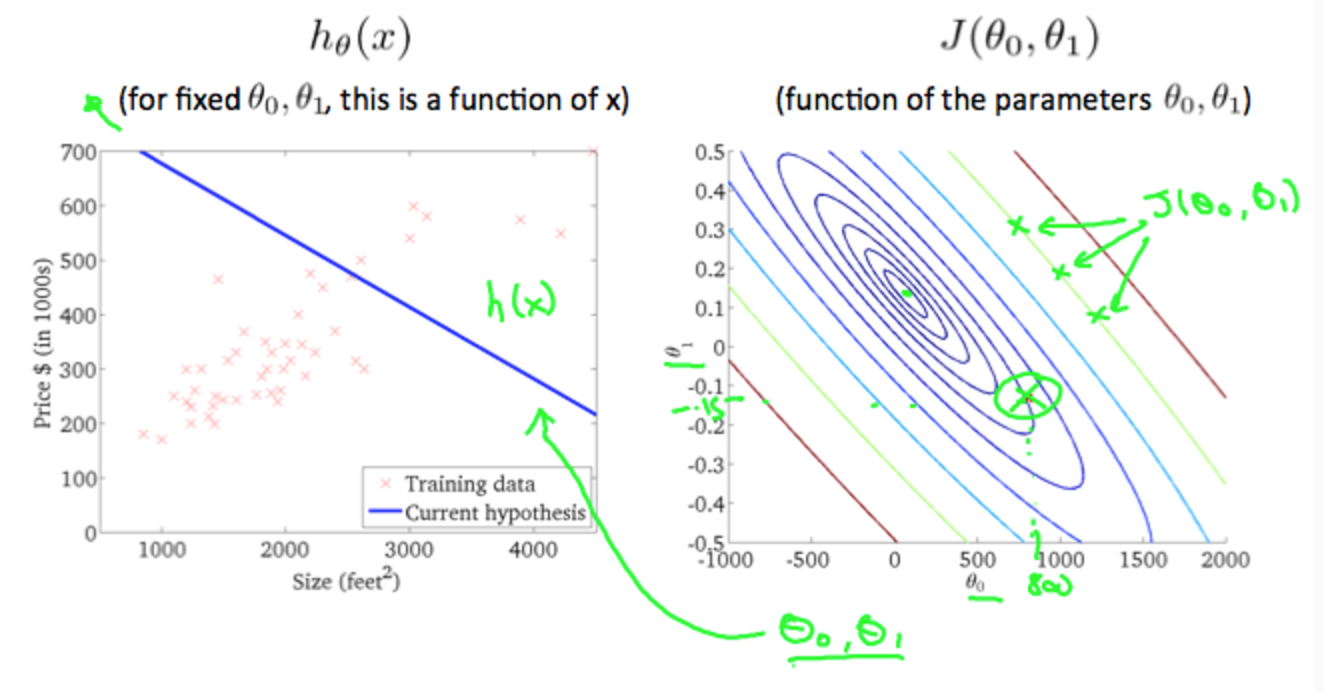
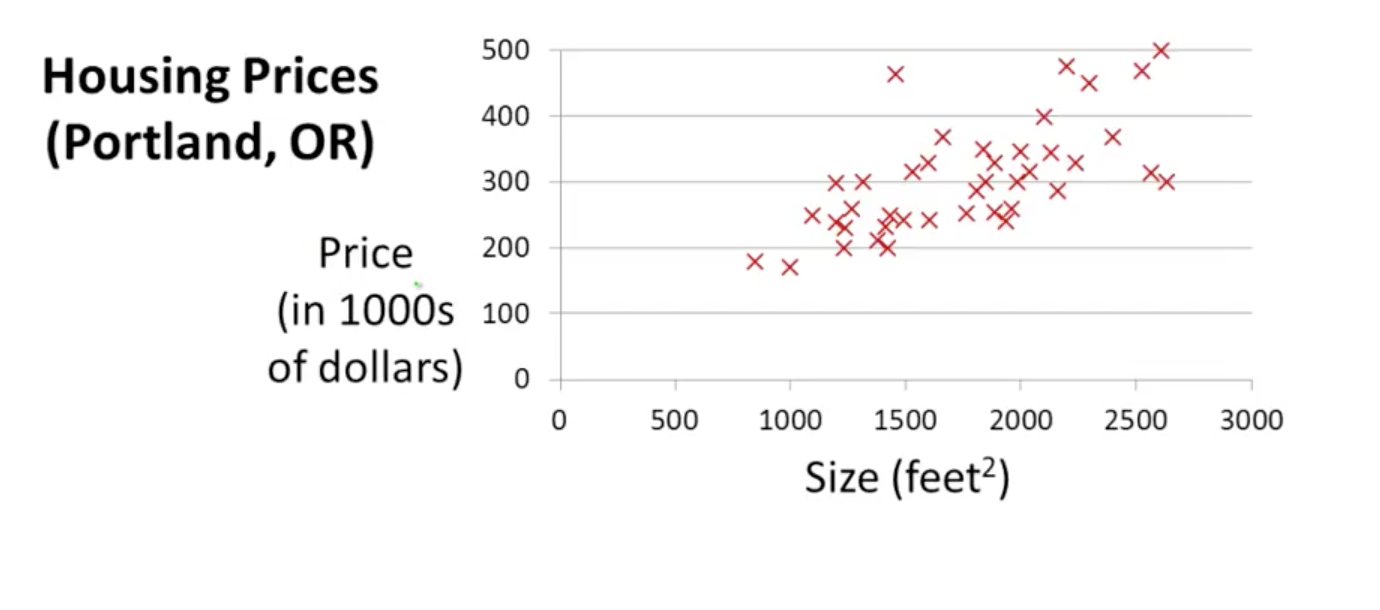
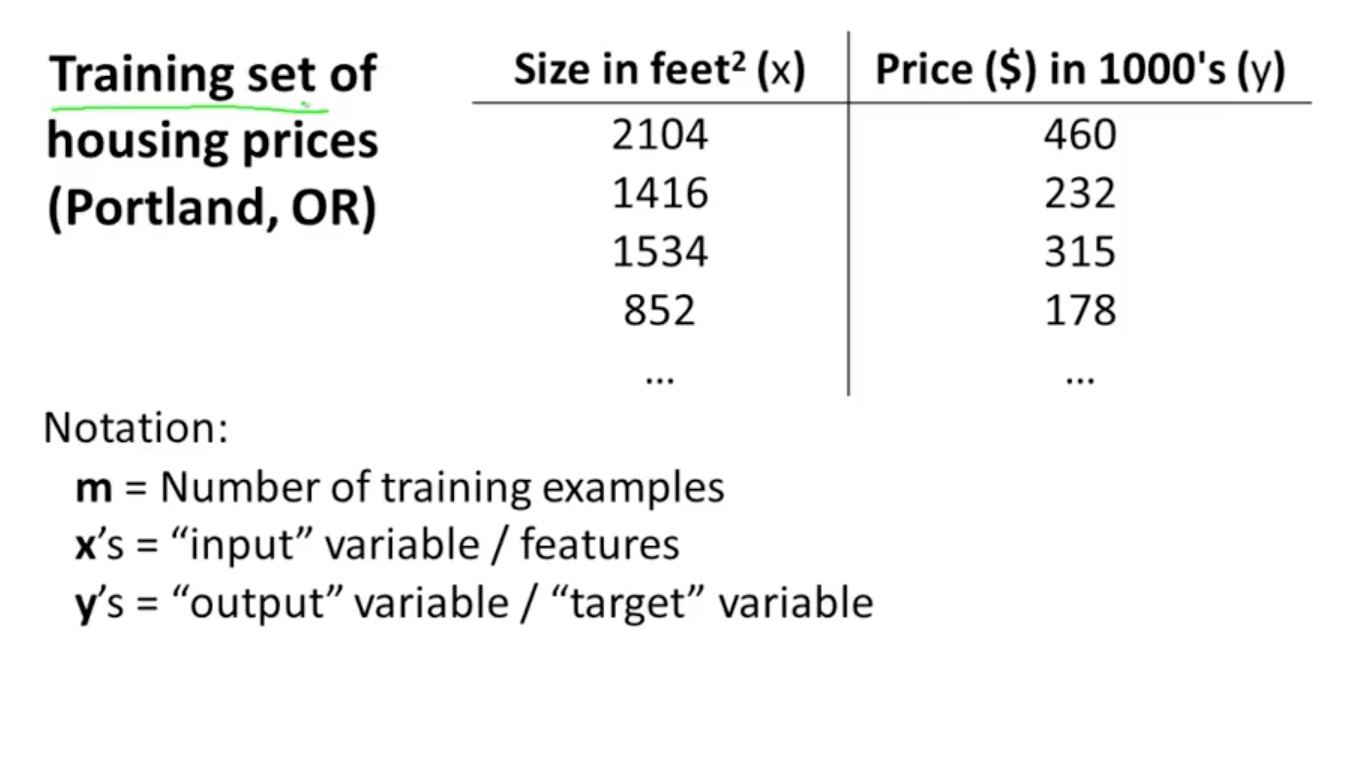
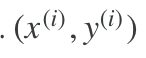 表示样本第i行样本数据。
表示样本第i行样本数据。